Advent of ML Day 5: Rerankers
12/5/2024
Cohere just released Rerank v3.5 and Pinecone just released Rerank v0. But what exactly are rerank models? How do they work? And how are they useful in a retrieval augmented generation (RAG) pipeline?
Yesterday, we explored hybrid search, combining BM25 algorithm with semantic search using embeddings. We discussed using reciprocal rank fusion (RRF) to merge results. Today, we'll dive into a more sophisticated approach: cross-encoder rerankers.
What are Rerankers?
Imagine you're searching through a massive library. First, you quickly scan the shelves for potentially relevant books (this is like BM25 or embedding search). Then, you pick up each promising book and carefully examine its contents, ordering them by relevance (this is reranking).
While initial retrieval needs to be fast and work with potentially millions of documents, reranking only needs to handle the top-k results (usually 20-100 documents), allowing us to use more sophisticated models.
From Bi-Encoders to Cross-Encoders
Embedding models (like those we discussed on Day 3) are bi-encoders: they encode queries and documents separately into vectors and then compare with a nearest neighbor search. This approach is computationally efficient but misses more subtle relationships.
Cross-encoders look at the query and document together, enabling them to be more nuanced. The trade-off? They're much slower, which is why we use them only for reranking a small set of documents during any one search.
Rerankers are built on large language models fine-tuned specifically for relevance ranking. They typically:
- Take a query-document pair as input
- Process them together through multiple transformer layers
- Output a relevance score
For Cohere's latest model, they've focused training on specific fields like finance and legal, along with including many more examples of structured data (JSON, XML etc). Recent rerankers are also multi-lingual and much better at handling non-English documents.
Fun fact: you can actually trick any LLMs into ranking documents by restricting the tokens that they can output. Restricting the output to a binary Yes or No for relevance and then using the logprobs as a score is a simple way to do this. Here is the OpenAI cookbook doing just that using their completions API.
Retrieval Pipeline
With hybrid search and a reranker, a typical pipeline looks like this:
- Initial Retrieval: Use fast methods (BM25/embeddings) to get top-k candidates
- Reranking: Apply cross-encoder to re-score candidates
- Final Ranking: Sort by final scores
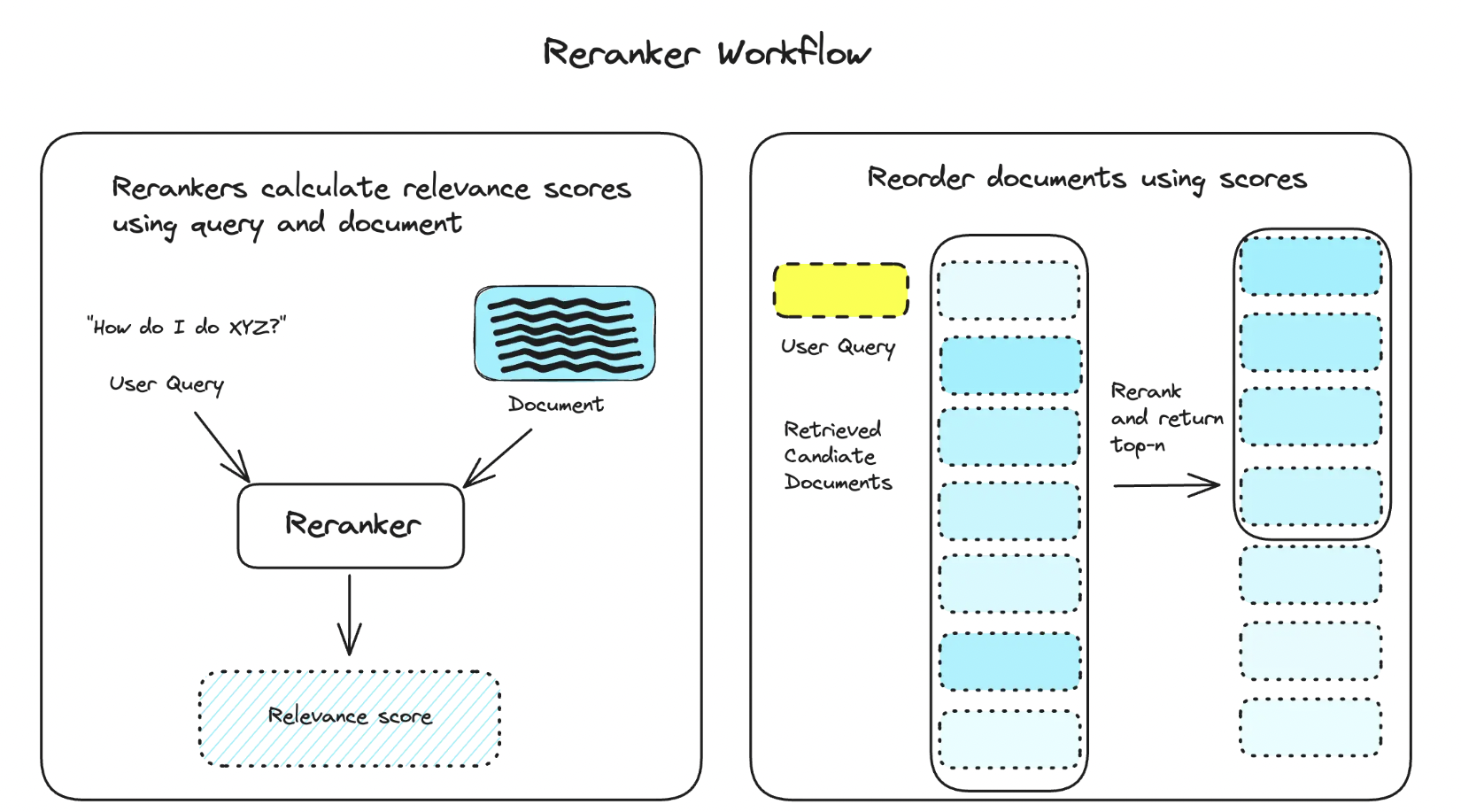
picture credit: Pinecone
Measuring Success
How do you know if your reranker is working? Common evaluation metrics for retrieval systems include:
- Mean Reciprocal Rank (MRR)
- Normalized Discounted Cumulative Gain (NDCG)
- Precision@k
You can also use an LLM as a judge (optionally finetuned) with a set of multi-shot examples. Hamel Hussain has a great blog post on this topic.
Tomorrow, we'll go into some more practical examples to evaluate your new retrieval system.
Happy day 5!
Matt
Resources:
Sign up for (very occasional) updates on new posts.